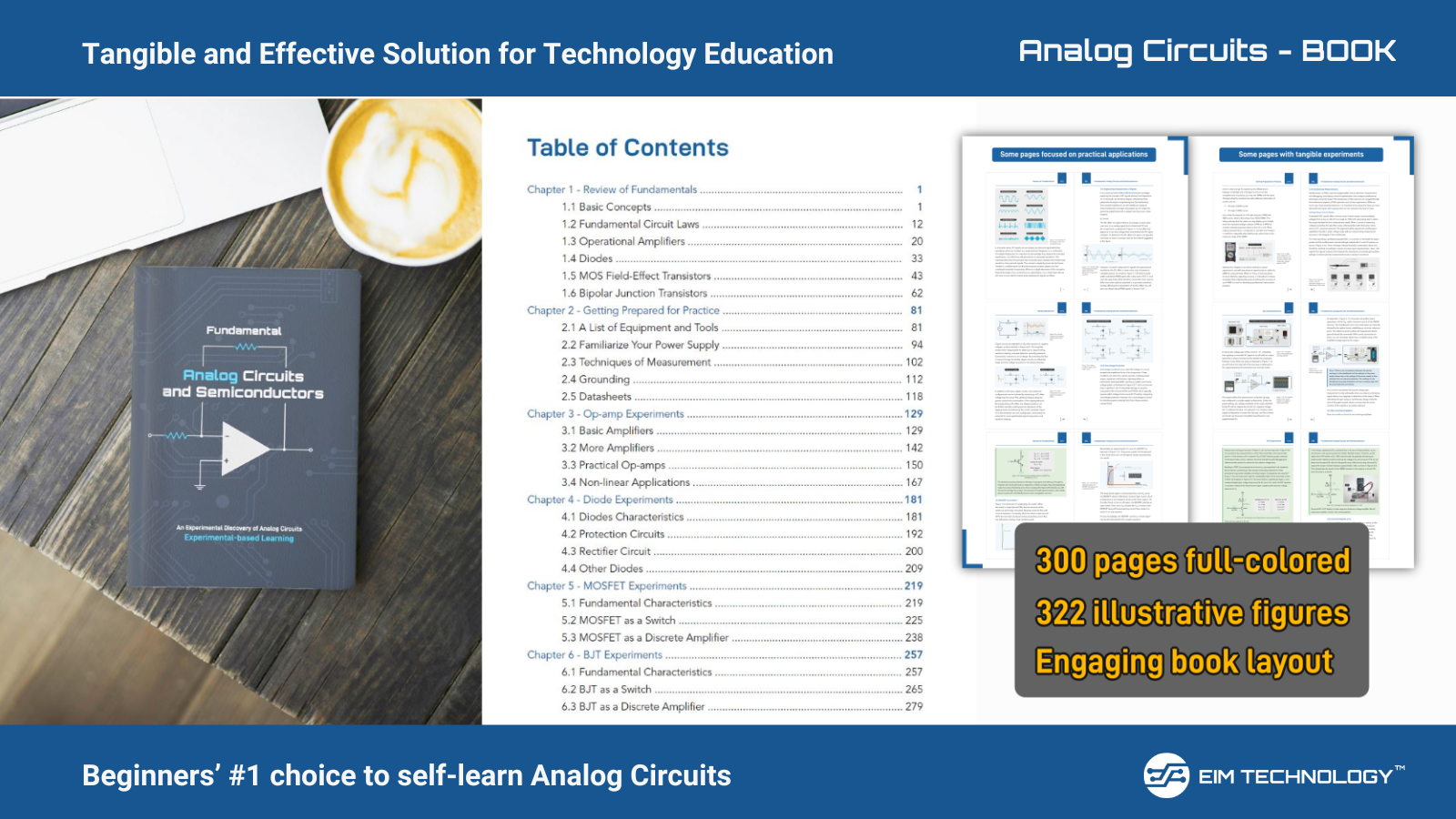
What is Convolutional Neural Network (CNN)
A Convolutional Neural Network (CNN) is a type of deep learning algorithm specifically designed to process structured data, such as images, videos, and even time-series data. CNNs have revolutionized fields like computer vision, medical imaging, autonomous vehicles, and more by achieving exceptional accuracy in tasks like image recognition, object detection, and segmentation.
Convolutional Neural Networks: Layers and Functionality
The layered structure of Convolutional Neural Networks (CNNs) can be understood as a step-by-step process of extracting, refining, and analyzing information. Each layer serves a specific purpose, gradually transforming raw data into meaningful insights. Like building with Lego blocks, neural networks are built in multiple stacked layers. The input layer acts like your eyes, receiving raw images, hidden layers function like different brain regions, analyzing and processing information, and the output layer makes the final judgment, telling you what it sees.
- Input Layer:
The input layer is where raw data, such as an image, enters the network. Images are typically represented as three-dimensional arrays, including height, width, and color channels. For instance, an RGB image might have dimensions of 224×224×3224 \times 224 \times 3224×224×3, representing its pixel resolution and three color channels (red, green, and blue).
The purpose of the input layer is to standardize and prepare this raw data for processing. The image data might be normalized (e.g., pixel values scaled to the range [0, 1]) or resized to fit the input dimensions expected by the CNN. This ensures compatibility with the following layers.
- Hidden Layers
The hidden layers are the core of a CNN and consist of multiple sub-layers, each with a specific role. These include convolutional layers, pooling layers, and activation functions. Together, they work to extract and process features from the input data.
(a) Convolutional Layers
The convolutional layer is the heart of feature extraction. It applies filters (also called kernels) that slide over the image to identify patterns such as edges, textures, or more complex shapes. Each filter is designed to recognize specific features, and the output is a "feature map" highlighting areas of interest.
For example, one filter might detect horizontal edges, while another identifies vertical edges. These feature maps stack together, forming a multi-layered representation of the image.
Key Insight: The convolutional layer reduces the spatial complexity of the image while retaining the most critical features. The more layers, the more abstract the features become.
(b) Pooling Layers
Pooling layers simplify feature maps by reducing their dimensions, a process known as downsampling. This helps decrease computational load and ensures that the CNN focuses on dominant features, not exact pixel positions.
For instance, in max pooling, the layer divides the feature map into regions and retains only the maximum value from each region. This is akin to summarizing a large dataset by keeping only its most significant values.
Key Insight: Pooling provides spatial invariance, meaning the network becomes less sensitive to small shifts or distortions in the input image.
(c) Activation Functions
Activation functions introduce non-linearity into the network, allowing it to model complex patterns in the data. Common activation functions include ReLU (Rectified Linear Unit), which replaces negative values in the feature maps with zeros.
This step mimics biological neurons, where certain inputs activate the neuron, and others do not. Without activation functions, the CNN would only be able to learn linear relationships, which are insufficient for complex image recognition tasks.
Key Insight: Activation functions enable the CNN to learn intricate, non-linear mappings from inputs to outputs.
3. Output Layer
The output layer is the final step in the CNN. It translates the processed features from the hidden layers into the desired result, such as classifying an image or predicting values.
For classification tasks, the output layer often uses a Softmax function, which converts the outputs into probabilities. Each probability corresponds to the likelihood that the input belongs to a specific class. For binary classification tasks, a Sigmoid function is used, outputting a probability score between 0 and 1.
Example: If the CNN is trained to identify animals, the output layer might produce probabilities like "Cat: 90%, Dog: 5%, Other: 5%," indicating the network’s confidence in its prediction.
Convolution Neural Network
If traditional neural networks are "pixel perfectionists" trying to remember every detail in an image, then Convolutional Neural Networks (CNNs) are like experienced art critics. They don't get distracted by individual pixels but instead, look at overall features before focusing on important details.
Imagine admiring an impressionist painting, from a distance you see a beautiful garden, but up close you notice the delicate brushstrokes. CNN understands images through this same layered approach.
What is Convolution?
Convolution is a mathematical operation that combines an input image with a convolutional kernel (or filter) through a pointwise multiplication followed by summation. The primary goal of this operation is to extract local features such as edges, corners, textures, and other patterns that help identify the structure within the image.
The convolution operation is defined mathematically as:

● Input (i+m, j+n): Represents the pixel values in the image being analyzed.
● Kernel(m, n): A small matrix (e.g., 3x3 or 5x5) that slides across the image to detect specific patterns.
● Feature Map (i, j): The result of the convolution operation, also known as the activation map, highlights the regions where the kernel detected certain features.
How Convolutional Layers Works?
Imagine an art critic examining a masterpiece. They don't process the entire painting at once but instead scan it region by region to find the most critical details. Similarly, convolution operates locally, focusing on small, overlapping regions of the image.
● Sliding Window: The kernel moves systematically across the input image, examining one small region (patch) at a time. This process ensures every part of the image is analyzed.
● Pattern Matching: At each position, the kernel performs an element-wise multiplication with the corresponding patch of the input image and sums the result to produce a single value for the feature map.
● Revealing Features: The resulting feature map highlights regions where the kernel detects its target pattern, such as horizontal edges or texture gradients.
Visualizing Convolution
Suppose you are using a 3×33 \times 33×3 kernel to identify vertical edges.
1.Kernel Example: A Sobel filter for vertical edges might look like this:

2. Input Patch: Consider a portion of the image:

3. Convolution Operation: Multiply each kernel value by the corresponding pixel in the patch and sum the results:

You can look into the specific calculation process in the figure below in more detail. That is, how is the output result 1 in the above figure calculated?
In fact, similar to wx + b, w corresponds to the filter Filter w0, x corresponds to different data windows, b corresponds to Bias b0, equivalent to the filter Filter w0 and one by one data window multiplication and then summing, and finally add the Bias b0 to get the output result of 1, as shown in the following process:


- The left part shows the input image with dimensions 773, where 7*7 represents the image pixel dimensions (width/height) and 3 represents the depth - corresponding to R, G, B color channels.
- The data window moves with a stride of 2, taking 3*3 local patches of data, with zero-padding=1.
- The middle part shows two different filters (Filter w0 and Filter w1) corresponding to two neurons, with depth=2.
- The rightmost part shows the two different outputs.
Convolutional Neural Network Example: Applying CNN to an Image
Step 1: Extracting Low-Level Features
The first stage of a Convolutional Neural Network (CNN) focuses on detecting low-level features like edges, lines, and corners. This is done through the convolutional layer, where filters, also known as kernels, slide over the image systematically. At each position, the filter calculates a mathematical operation called convolution, resulting in a new representation called a feature map. These feature maps emphasize areas in the image that match the filter’s pattern, making basic geometric shapes more prominent.
To understand this, think about looking at a detailed painting. Initially, your eyes catch simple outlines and patterns, such as sharp lines or curves. Similarly, CNNs start by identifying foundational features, like the triangular edges that might form a cat's ears. This step is fundamental as it lays the groundwork for more complex patterns to be built in later stages.
Step 2: Combining Mid-Level Features
Once basic features are identified, the CNN’s intermediate layers begin to combine them into more complex structures. These layers process the low-level feature maps from the previous step, creating new feature maps that represent localized patterns, such as textures, shapes, or object parts. Pooling layers may follow the convolutional layers to reduce the spatial size of these feature maps, retaining only the most critical information.
This step is analogous to observing a painting more closely. You notice that below the sharp triangular shapes (the cat's ears), there’s a circular outline with symmetrical markings that resemble a cat’s face. The CNN mirrors this behavior, aggregating low-level edges and lines into meaningful patterns, such as the contours of eyes, whiskers, or fur texture. These mid-level features provide the building blocks for recognizing objects.
Step 3: High-Level Semantic Understanding
In the final stages, the CNN synthesizes all the extracted features into a holistic understanding of the image. Fully connected layers take the output from the previous convolutional and pooling layers and flatten it into a one-dimensional feature vector. This vector represents the image’s overall characteristics, which the network then processes to classify the object. Activation functions like Softmax convert the vector into a probability distribution, with each value corresponding to the likelihood of the image belonging to a specific class.
At this point, the CNN behaves like a detective piecing together evidence. It integrates the triangular ears, the circular face, and the symmetrical patterns into a complete picture. The CNN recognizes these combined features as definitive markers of a cat and confidently concludes, “This is a cat.” This step demonstrates how CNNs can interpret an image’s context and make accurate predictions by synthesizing details from previous layers.
Step 4: Recap of the Process
The CNN processes an image through a hierarchical sequence of steps, starting with low-level feature extraction, moving to mid-level feature combinations, and ending with high-level semantic understanding. Each layer adds a new level of abstraction, transforming raw pixel data into meaningful information. By mimicking the human brain’s ability to process visual information in stages, CNNs excel at tasks like image recognition, object detection, and segmentation. Through this systematic approach, CNNs unlock the secrets hidden within images, revealing their meaning with remarkable precision.


Types of convolutional neural networks
The story of CNN architectures is one of continuous innovation and breakthrough. Each new model pushed the boundaries of what artificial intelligence could achieve in computer vision. Let's explore these groundbreaking architectures and understand how they transformed the field.
1) LeNet: The Pioneer That Started It All
In 1998, when most researchers were skeptical about neural networks, Yann LeCun introduced LeNet-5. This pioneering architecture proved that CNNs could solve real-world problems. Originally designed for reading zip codes and checking digits, LeNet demonstrated remarkable accuracy in recognizing handwritten numbers.
What made LeNet special?
Its elegant five-layer architecture introduced two fundamental concepts we still use today: convolutional layers and pooling layers. Think of it as the Wright brothers' first airplane - while simple by today's standards, it laid the groundwork for everything that followed.
2) AlexNet: The Revolutionary
2012 marked a turning point in computer vision history. AlexNet didn't just win the ImageNet competition; it crushed it, reducing the error rate by an astounding margin. This was the moment when deep learning proved it could surpass traditional computer vision methods.
AlexNet's success came from several innovations. It introduced ReLU activation functions, making training faster and more effective. The network also used dropout to prevent overfitting - imagine a teacher randomly hiding parts of a textbook to ensure students truly understand the material rather than memorizing it.
3) VGG: Beauty in Simplicity
The Visual Geometry Group at Oxford took a different approach with VGG in 2014. Instead of introducing complex new elements, they asked: "What if we keep things simple but go deeper?" The result was an architecture of striking elegance.
VGG used only 3x3 convolution filters throughout its network, stacked to remarkable depth. This uniformity made it both powerful and beautiful - like a master chef creating an exquisite dish using just a few basic ingredients. Its clarity of design made it a favorite among researchers and practitioners alike.
ResNet: Breaking the Depth Barrier.
By 2015, everyone knew deeper networks could learn more complex patterns. But training very deep networks seemed impossible - they would simply stop learning. Microsoft Research's ResNet solved this fundamental problem.
The key insight? Skip connections, or "residual learning." Imagine building a skyscraper where each floor can look at both the floor below and several floors down. This simple yet brilliant idea allowed ResNet to reach unprecedented depths - up to 152 layers and beyond.
Convolutional neural networks and computer vision
Computer vision has been revolutionized by deep learning, transforming how we interact with technology in our daily lives. Self-driving vehicles use it to detect and avoid obstacles, analyzing their surroundings in real-time to identify pedestrians and other vehicles. The technology has also made facial recognition remarkably accurate - something you experience every time you unlock your phone with your face or use a smart door lock.
Consider your smartphone's photo-sharing apps. Behind the scenes, deep learning algorithms work tirelessly to enhance your experience. They analyze millions of images to show you the most relevant and visually appealing content. Whether it's mouthwatering food photos, luxurious hotel rooms, or breathtaking landscapes, these algorithms learn your preferences and curate content specifically for you.
This technology goes beyond simple image classification. Modern computer vision systems can understand context, recognize emotions, detect subtle details, and even generate image descriptions. Social media platforms use these capabilities to automatically tag photos, filter inappropriate content, and improve accessibility for visually impaired users.
The impact of deep learning in computer vision extends far beyond consumer applications. In healthcare, it helps diagnose diseases through medical imaging. In manufacturing, it powers quality control systems. In agriculture, it monitors crop health. Each application demonstrates how this technology is quietly reshaping our world, making systems smarter and more responsive to human needs.
Advantages of CNNs
Think of CNNs as a super-efficient detective:
- Shared Clues
CNNs use parameter sharing, allowing the same filter (kernel) to detect features across different parts of an image. This efficiency reduces the number of parameters while enabling the network to recognize features like edges or textures regardless of their position in the input.
- Attention to Detail
By stacking multiple convolutional layers, CNNs progressively extract increasingly complex features, from basic edges to intricate patterns. This hierarchical processing captures subtle yet critical details that are essential for accurate predictions.
- Strong Adaptability
CNNs excel at recognizing objects regardless of their spatial arrangement. Techniques like pooling and convolutional layers help them maintain robustness to translations, rotations, and slight distortions in images.
- Self-Learning
CNNs automatically learn key features directly from raw data during training without requiring manual feature extraction. This capability significantly reduces the workload for engineers and allows the model to adapt to complex patterns effectively.
- High Efficiency in Feature Recognition
Through their ability to focus on relevant parts of the image while ignoring unnecessary details, CNNs make efficient use of computational resources to identify significant features, ensuring strong performance across diverse tasks.
- Wide Application Scope
CNNs power a broad range of applications, from medical imaging and autonomous vehicles to facial recognition and industrial quality control, showcasing their versatility and transformative impact across industries.
Disadvantages of CNNs
Of course, even our "AI detective" has its weaknesses:
1. Requires Large Training Samples
CNNs need extensive labelled datasets to learn effectively, much like a detective requires many case studies to refine their skills. Insufficient data can lead to overfitting or poor generalization, especially in complex tasks.
2. High Computational Demand
Training CNNs involves a vast number of operations, requiring powerful GPUs or TPUs. This computational intensity is akin to needing a super-sized "brain" to process and analyze data, which may limit accessibility for smaller-scale projects.
3. Overthinking Irrelevant Features
CNNs sometimes "overthink" by treating irrelevant features as important clues. This can lead to overfitting, where the model performs well on training data but struggles with unseen data.
4. Black-Box Nature
The decision-making process of CNNs is often opaque, making it challenging to understand or explain their judgments. This lack of interpretability is particularly concerning in critical applications like healthcare and autonomous vehicles.
5. Memory Intensity
Storing weights, biases, and intermediate feature maps requires substantial memory. For deep networks like ResNet or EfficientNet, this can be a challenge, particularly on edge devices with limited storage.
6. Invariance Limitations
While CNNs are robust to small variations like translation and rotation, they may struggle with more significant distortions or occlusions unless explicitly trained for those scenarios using augmented data.
7. Domain-Specific Challenges
CNNs often need retraining or fine-tuning when applied to a new domain. A model trained on natural images may not perform well on medical X-rays without significant adjustment.
Despite CNN’s limitations, CNNs remain a cornerstone of modern deep learning. Their ability to process and analyze visual data with remarkable accuracy and efficiency has propelled advancements in technology, from autonomous systems to healthcare. While challenges like computational cost and explainability persist, ongoing innovations in algorithms and hardware are steadily overcoming these barriers, enabling CNNs to become even more versatile and impactful in diverse applications.
FAQs
1. What is a Convolutional Neural Network (CNN)?
A. Convolutional neural network is a special type of deep feedforward neural network, particularly well-suited for processing grid-like data structures, mostly images. By mimicking the way the visual cortex in the human brain works, it uses local connections and weight sharing to effectively reduce the complexity of the network and improve the efficiency of feature extraction. A typical CNN consists of an input layer, convolutional layers, pooling layers, fully connected layers, and an output layer. By stacking multiple layers, complex neural network models can be built.

2. How do CNNs work?
A. CNNs work by applying filters to input data through convolution operations, followed by pooling layers to reduce dimensionality. This process creates feature maps that capture increasingly complex patterns, which are then used for classification or detection tasks.

3. What is the difference between CNN and convolution?
A. Convolution is a mathematical operation that combines two functions to produce a third function. A CNN is a complete neural network architecture that uses convolution operations as its core building block, along with other components like pooling and fully connected layers.
4. What is the basic principle of CNN?
A. The basic principle of CNN is to automatically learn hierarchical feature representations from data using convolution operations, allowing the network to understand complex patterns while maintaining spatial relationships.
5. What is convolution and its types?
A. Convolution in CNNs comes in several forms:
- Standard Convolution
- Depthwise Convolution
- Pointwise Convolution
- Dilated Convolution
- Transposed Convolution
6. How many layers are in CNN?
A. A typical CNN contains multiple types of layers:
- Input Layer (1)
- Convolutional Layers (multiple)
- Pooling Layers (usually after each conv layer)
- Fully Connected Layers (typically 1-3)
- Output Layer (1)
The total number of layers varies by architecture, from shallow networks with 5-6 layers to deep networks with over 100 layers.